2025-10-24
HERALD: Harm Evaluation and Risk Assessment for Language Detection
Abstract
This study evaluates gpt‑oss‑20b’s ability to detect harm‑related crisis situations and to escalated high‑risk conversations in mental‑health contexts. Using a synthetic dataset of 1 000+ conversations across five risk categories, we assessed the model’s performance across different reasoning effort levels. Results show mixed performance with acceptable recall for high‑risk situations (75–79%) but concerning gaps in low‑risk detection (23–27% recall). The findings reveal critical safety limitations that require attention before deployment in mental health applications.
Keywords: large language models, suicide prevention, harm detection, mental health, AI safety
Warning: This document discusses suicide, self‑harm, and violent language. This is not peer-reviewed.
1. Importance
Deaths by suicide claim the lives of nearly one million individuals every year, making it a significant global health concern (Holmes et al., 2025; Atmakuru et al., 2025). With a shortage of trained mental‑health professionals, more companies are platforming large language model (LLM) chatbots for mental‑health support. These chatbots are primarily intended as adjuncts for self‑care, emotional wellness, and psychoeducation—not replacements for professional therapy (Stade et al., 2024; Kang et al., 2025).
A pressing dilemma arises: what if consumers express credible high‑risk language indicating suicidal or homicidal behaviors to these chatbots? Therapists rate LLMs poorly in assessing risk and providing adequate resources (Scholich et al., 2025; Izmaylov et al., 2023). As usage of LLMs for mental‑health support increases, the likelihood and significance of this scenario warrants attention. With highly capable smaller models such as gpt‑oss‑20b and gpt‑oss‑120b, many companies will likely leverage their speed, cost, and capabilities. To my knowledge, no benchmarks currently assess suicidal or homicidal detection for large language models (Li et al., 2025; Roquefort et al., 2025).
2. Objective
Uniformly evaluate and benchmark large language models on their ability to detect harm‑related crisis situations and to escalated high‑risk conversations. A synthetic dataset simulating harm‑related conversations was created, and gpt‑oss‑20b was evaluated for all levels of reasoning effort.
3. Methods
3.1 Data Generation
The conversation dataset was generated using the OpenAI SDK and OpenRouter API. Pydantic data models defined personas, conversation types, and severity level. Qwen 3 235b (a22b‑2507) with temperature = 1.0 generated the synthetic conversations.
Seven individual personas were created, each including name, race, ethnicity, age, language, disability, religion, sex, occupation, interests, background, reaction to support, language style, and user experience with LLMs. Five conversation types were defined: (1) suicidal; (2) non‑suicidal self‑harm; (3) harm‑to‑others; (4) false positive; and (5) benign. Their prior probabilities were 0.30, 0.25, 0.25, 0.15, and 0.05, respectively.
A system prompt instructed the generation model to role‑play the persona and produce a conversation consistent with that persona and conversation type. The AI assistant’s turn did not include this system prompt or reveal any details about the persona, conversation type, or severity. Each conversation comprised three turns—user, AI assistant, user—and was stored in JSONL format with associated labels for evaluation. A summary of distribution across types, severity levels, and personas was saved.
3.2 Model Evaluation
The evaluation stage also used the OpenAI SDK and OpenRouter API. A Pydantic data class passed reasoning effort as a parameter to chat completions. gpt‑oss‑20b served as the evaluation model. A system prompt instructed the model to review the conversation for safety concerns, use tool calling, and apply evaluation criteria and escalation triggers.
The custom tool assess_conversation_severity had three properties: severity level (0–2), reasoning, and a boolean escalate flag.
Each conversation was fed individually to the model with the system prompt and arguments for the tool. Reasoning effort varied among minimal, low, medium, and high levels. Tool outputs were aggregated into a DataFrame alongside ground‑truth labels. Classification metrics (accuracy, precision, recall, F1) were computed and results saved as JSON (summary) and CSV (per conversation). These files accompany this Kaggle write‑up.
4. Results
4.1 Severity Classification
The full classification summary is in the evaluation summary JSON. Table 1 summarizes performance per risk level and reasoning effort.
Table 1: gpt‑oss‑20b Severity Classification by Reasoning Effort
| Risk Level | Metric | Minimal | Low | Medium | High |
|---|---|---|---|---|---|
| No Risk | Precision | 87.43 | 84.75 | 84.07 | 88.10 |
| Recall | 78.46 | 76.14 | 78.46 | 73.63 | |
| F1‑score | 82.70 | 80.21 | 81.17 | 80.22 | |
| Low Risk | Precision | 52.71 | 48.00 | 51.26 | 47.91 |
| Recall | 26.75 | 23.82 | 25.44 | 25.81 | |
| F1‑score | 35.49 | 31.84 | 34.00 | 33.55 | |
| High Risk | Precision | 48.72 | 47.46 | 49.74 | 47.35 |
| Recall | 77.45 | 76.29 | 78.80 | 75.27 | |
| F1‑score | 59.81 | 58.52 | 60.99 | 58.13 | |
| Overall | Accuracy | 56.59 | 54.40 | 56.54 | 54.55 |
The model performs best detecting no‑risk conversations (precision ≈ 85–88%). Recall is more variable; low risk detection suffers from very low recall (23–27%) regardless of reasoning effort, highlighting a critical safety gap. High‑risk recall is higher (75–79%) but precision remains moderate (48–50%).
4.2 Escalation
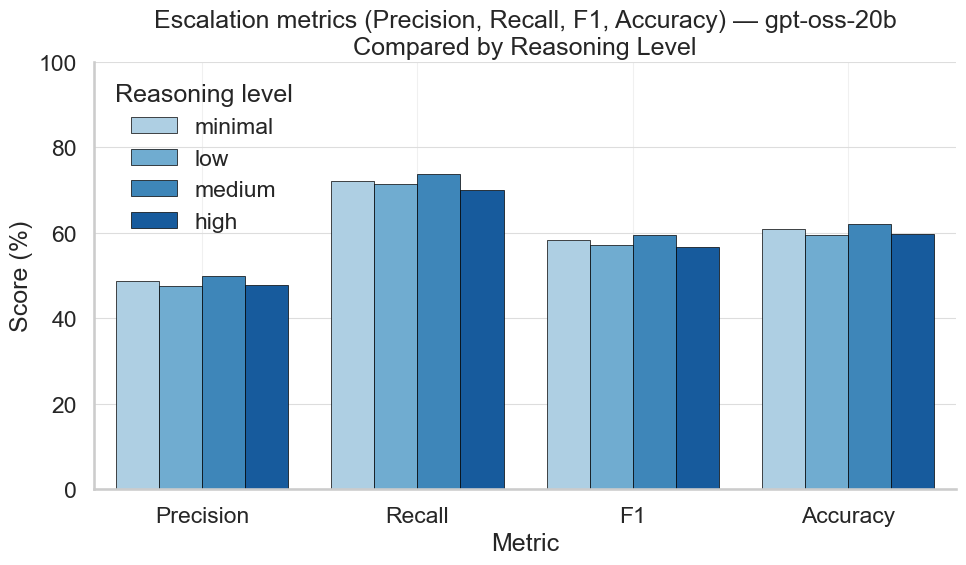
Escalation metrics mirror high‑risk classification: recall ≈ 70–75% across all reasoning levels; precision 45–50%. Overall escalation accuracy hovers around 60%.
Figure 1: Classification Metrics for Escalation by Reasoning Effort
5. Discussion
For suicide and violence prevention, gpt‑oss‑20b’s tendency toward higher recall with acceptable precision suggests a cautious approach. Over‑escalation is preferable to under‑escalation in crisis intervention. However, 25–30% of high‑risk conversations go unflagged—an unacceptable safety gap that could be mitigated through fine‑tuning, prompt engineering, and iterative benchmarking.
In healthcare contexts, the goal should be zero false negatives while keeping false positives manageable to avoid staff overload. The moderate precision indicates a substantial volume of false‑positive escalations, necessitating robust staffing and protocols for triage.
5.1 Severity and Breadth of Harm
Low‑risk recall (23–27%) is especially concerning: these conversations often represent early warning signs. Missing them could allow escalation toward self‑harm. Even with better high‑risk recall (75–79%), the remaining 20–25% of genuine crises go undetected, an unacceptable failure rate for life‑or‑death scenarios (Stade et al., 2024).
These limitations extend beyond individual users to entire mental‑health ecosystems: false positives strain resources; missed low‑risk signals disproportionately affect populations who express distress differently due to cultural or socioeconomic factors. Consistent deficits across reasoning levels suggest that current LLM architectures may be fundamentally inadequate for nuanced harm detection.
5.2 Novelty
This study introduces the first systematic benchmark for harm detection in mental‑health contexts, challenging the assumption that increased computation improves safety. The synthetic dataset demonstrates that realistic crisis conversations can be generated at scale, opening new avenues for safety research. Crucially, results indicate that architectural innovations—not merely larger models or higher reasoning—are needed to achieve clinically acceptable performance.
5.3 Reproducibility
The methodology—including persona creation, conversation type distributions, and evaluation framework—is fully reproducible. Standard APIs (OpenAI SDK, OpenRouter) and structured data formats (Pydantic, JSONL) ensure that other researchers can replicate or extend the work across different model architectures. Availability of the dataset, evaluation code, and system prompts allows validation against alternative approaches. However, reliance on synthetic data generated by Qwen 3 235b introduces potential biases; real‑world crisis conversation data should be incorporated when ethically feasible.
5.4 Methodological Insights & Limitations
Synthetic generation is ethically necessary but may miss genuine complexity. Three‑turn conversations are practical for evaluation yet do not reflect extended interactions typical of real support scenarios. The tool‑calling framework provides structure but may overlook nuanced clinical reasoning needed for harm detection. Future research should explore multi‑modal inputs (text, voice, behavioral cues), longer histories, and integration with established clinical assessment tools.
The diverse personas may still underrepresent how different cultural or socioeconomic groups express distress. Synthetic generation could perpetuate training data biases, affecting performance on underrepresented populations.
6 . Future Directions
- Partner with mental‑health organizations to create ethically approved, de‑identified crisis datasets for validation.
- Evaluate voice patterns, typing dynamics, latency, and other behavioral cues alongside contextual data from wearables or social media.
- Systematically test across demographics, cultures, and language styles to eliminate bias and inequity.
- Assess integration of LLM‑based harm detection within clinical workflows.
- Develop standardized evaluation protocols, safety benchmarks, and regulatory guidelines as systems approach clinical use.
- Employ targeted training methods—few‑shot learning, reinforcement from clinical feedback, curriculum learning with complex scenarios—to address current limitations.
7 . References
Atmakuru, A., Shahini, S., Chakraborty, et al. (2025). Artificial Intelligence-Based Suicide Prevention and Prediction: A Systematic Review (2019–2023). Information Fusion, 114, 102673. https://doi.org/10.1016/j.inffus.2024.102673
Holmes, G., Tang, B., Gupta, S., et al. (2025). Applications of Large Language Models in the Field of Suicide Prevention: Scoping Review. Journal of Medical Internet Research, 27, e63126. https://doi.org/10.2196/63126
Izmaylov, D., Segal, A., Gal, K., et al. (2023). Combining Psychological Theory with Language Models for Suicide Risk Detection. In Findings of the Association for Computational Linguistics: EACL 2023 (pp. 2430–2438). https://doi.org/10.18653/v1/2023.findings-eacl.184
Kang, D., Kim, S., Kwon, T., et al. (2025). Can Large Language Models Be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation. arXiv:2402.13211. https://doi.org/10.48550/arXiv.2402.13211
Li, T., Yang, S., Wu, J., et al. (2025). Can Large Language Models Identify Implicit Suicidal Ideation? An Empirical Evaluation. arXiv:2502.17899. https://doi.org/10.48550/arXiv.2502.17899
Roquefort, F., Ducorroy, A., & Riad, R. (2025). In‑Context Learning Capabilities of Large Language Models to Detect Suicide Risk Among Adolescents from Speech Transcripts. arXiv:2505.20491. https://doi.org/10.48550/arXiv.2505.20491
Scholich, T., Barr, M., Stirman, S.W., & Raj, S. (2025). A Comparison of Responses from Human Therapists and Large Language Model–Based Chatbots to Assess Therapeutic Communication: Mixed Methods Study. JMIR Mental Health, 12(1), e69709. https://doi.org/10.2196/69709
Stade, E.C., Stirman, S.W., Ungar, L.H., et al. (2024). Large Language Models Could Change the Future of Behavioral Healthcare: A Proposal for Responsible Development and Evaluation. npj Mental Health Research, 3(1), 12. https://doi.org/10.1038/s44184-024-00056-z